




















Science at work 15 July 2026

© R. Carayol
Le déluge des données présentes sur le web ouvre de nouveaux défis dans notre monde ultra numérisé. Cette masse de données représente une mine d’informations qui peut être traitée de manière automatique en mobilisant des méthodes d’IA (intelligence artificielle). Dans nos travaux, nous utilisons de telles approches pour analyser automatiquement des masses de données variées (textes, images, vidéo, bases de données, etc.). Nos recherches ont par exemple permis de mieux comprendre des problèmes d’insécurité alimentaire au Burkina Faso ou des questions d’aménagement du territoire en France à partir de textes en français (articles de presse, textes règlementaires des collectivités publiques, etc.).
À partir de ces données hétérogènes, les approches d’IA peuvent produire automatiquement des analyses de très bonne qualité, mais sans que l’utilisateur (expert ou non) puisse réellement expliquer ou comprendre la raison pour laquelle certains résultats ont été obtenus. C’est ce que l’on appelle l’effet « boite noire ». Les résultats qu’une IA telle que ChatGPT peut générer automatiquement est un bon exemple de cet effet boîte noire.
Le but de nos travaux est d’étudier de quelle manière les données textuelles (dépêches, articles scientifiques, sites web, etc.) et les méthodes de traitements associées (fouille de textes) peuvent être mobilisées pour améliorer les interprétations des résultats obtenus par les approches IA.
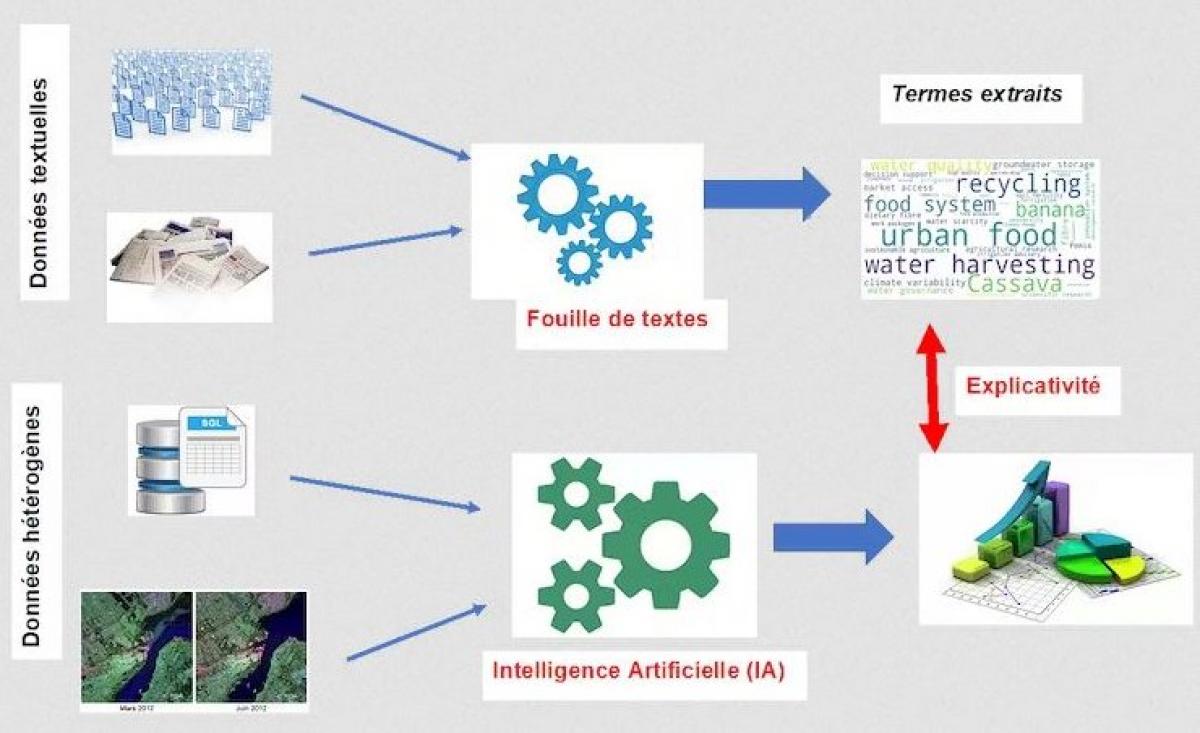
Schéma de l'approche expérimentale de l'étude.
De façon plus précise, l’intégration des données hétérogènes liées à la sécurité alimentaire peut contribuer à améliorer les systèmes d’alerte. Ceci a été mis en œuvre au cours de la thèse d’Hugo Deléglise en Science des Données qui a été menée au CIRAD et avec l’Institut de Convergences #DigitAg et qui s’intéresse à l’agriculture numérique. Les travaux ont consisté à collecter, rassembler, fusionner des données hétérogènes (images satellitaires, données économiques, données météorologiques, densité de population, etc.) avec des méthodes d’IA pour prédire des scores de consommation et de diversité alimentaire au Burkina Faso. Le score de consommation alimentaire représente la fréquence de consommation de différents groupes alimentaires (céréales, légumes, fruits, protéines animales, etc.) d'un ménage sur 7 jours. Le score de diversité alimentaire indique le nombre de groupes d’aliments consommés au cours des dernières 24 heures. Les méthodes produites dans ces travaux mettent en avant des résultats, mais en omettant souvent l’effet explicatif associé. Ainsi, nous pouvons par exemple prédire des indices d’insécurité alimentaire fondés sur les scores de consommation et diversité alimentaires (vision quantitative), mais sans apporter les explications sur les raisons associées à des problèmes identifiés (vision qualitative).
C’est pour améliorer ces aspects que nos propositions ont consisté à intégrer (collecter, standardiser et analyser) des données issues de la presse du Burkina Faso (Burkina24, LeFaso) sur une période donnée (2009-2018). Les 22856 articles collectés en français ont été analysés de manière automatique avec des dictionnaires dédiés traitant de sécurité alimentaire accompagnés de méthodes statistiques et linguistiques. Ces dernières ont permis d’identifier des termes dits discriminants (c’est-à-dire fréquents et spécifiques à des textes et/ou périodes), mais également des termes véhiculant une opinion positive ou négative.
Ainsi, cette combinaison de ressources et approches mise en place dans un processus original souligne les raisons d’une insécurité alimentaires (conflits, invasion de criquets, inondation, etc.). La fouille de nos textes a par exemple mis en relief des mots-clés liés à la sécheresse en 2012 et un vocabulaire propre aux conflits et déplacements en 2013.
Par ailleurs, une analyse fine selon les périodes et les régions a également été conduite (illustration ci-dessous). Pour mener de telles analyses spatio-temporelles, il est au préalable nécessaire d’extraire, dans le contenu des textes, des informations précises comme les lieux. Pour cela, nous utilisons des méthodes de reconnaissance d’entité nommées. De manière générale, nous appelons une entité nommée un lieu, une personne, une organisation, etc. Notons également que les outils et ressources sont très riches pour traiter les textes en anglais, mais ils sont beaucoup moins dotés pour le traitement automatique des textes en français. Ceci constitue un défi très important dans nos travaux.

Image montrant les termes les plus discriminants selon 3 grandes Régions et 2 lexiques de sécurité alimentaire.
Pour résumer, en détectant une alerte avec des méthodes d'IA, nos approches fondées sur l'analyse des médias peuvent apporter des explications quant aux alertes identifiées.
Aussi, de nouvelles sources de données ont été récemment intégrées à notre processus, en particulier les données issues de YouTube. Celles-ci sont transcrites automatiquement en données textuelles avec des programmes informatiques. Les données transcrites automatiquement peuvent contenir des erreurs que l’on appelle bruit, qui compliquent l’application des méthodes de reconnaissances d’entités nommées. Par ailleurs, nous étudions actuellement l’opportunité d’intégrer d’autres types de données comme les données issues de la radio qui est un média très utilisé sur le continent africain.
Nous étudions également d’autres problématiques consistant à mettre en lien des données variées pour mieux analyser les processus d’aménagement du territoire en France qui sont abordées actuellement dans le cadre du projet HERELLES) (Hétérogénéité des données - Hétérogénéité des méthodes) financé par l'Agence nationale de la recherche (ANR).
Nos travaux permettent d’analyser de quelles manières, les règles d’urbanisme (par exemple, lorsqu’un bâtiment doit être construit, la présence d'une route est nécessaire) sont prises en compte dans la réalité.
Pour cela, deux défis technologiques et scientifiques sont à aborder : - Analyser automatiquement les textes règlementaires complexes écrits en français qui sont issus des Politiques Publiques - Mettre en lien ces textes avec les données satellitaires. Ces résultats menés en collaboration avec des unités de recherche de Montpellier (TETIS), Caen (GREYC) et Strasbourg (ICube) ont été présentés par Maksim Koptelov, chercheur post-doctorant en Science des Données, à la conférence très sélective DSAA (International Conference on Data Science and Advanced Analytics). Ces travaux issus du projet HERELLES pourront être intégrés dans des outils d’aide à la décision pour les collectivités locales afin de guider les analyses et les corrélations entre règlementations (par exemple, Plan Local d'Urbanisme) et la réalité du terrain pour accompagner les projets d'aménagement du territoire.
Les différentes approches résumées dans cet article mettent en avant que l’intégration de données textuelles dans ces systèmes complexes permet de mieux comprendre et éclairer des résultats obtenus avec des méthodes d’IA. Et de manière plus générale, les démarches, qui apportent une dimension explicative via les données textuelles ou autres approches, contribuent à lever certaines réticences à utiliser l’IA pour explorer et analyser les données issues de sources variées.
Science at work 15 July 2026

Science at work 1 July 2026

Science at work 23 June 2026